Welcome to my Next Gen GPU Blog
This site is about evolving graphics hardware into new domain spaces and architectures. We want
to deprecate the triangle as the atomic unit of 3d geometry and move to natural ways of defining content
(C) 2020 Atif Zafar
SIGGRAPH 2020 Panel Discussion
At SIGGRAPH 2020 (August 27, 10-11 am PDT) we will convene a Birds of a Feather (BOF) Panel entitled “Evolving Graphics Hardware Beyond the Triangle: What does the Next Generation Graphics Architecture Look Like“. The purpose of this BOF is to engage the community on defining the desired architectural features of a next-gen GPU architecture that would enable efficient use in new domain spaces such as spatial computing, mobile and embedded platforms, desktops and supecomputers. We want to fundamentally change the triangle-focused rasterization design into more general purpose rendering. We will have a panel of industry experts discussing pertinent issues related to next-gen GPUs.
Slides: https://www.pixilica.com/post/pixilica-s-founder-atif-zafar-to-give-a-talk-at-siggraph-2020
The table and diagram on the right panel describes what some of the new discussed features may look like. We propose a new programming language we call CG++ (C++ for GPUs) that evolves the C++ standard to program the specific features of GPUs. Some of the key advantages of this paradigm would be the development of new DSLs (domain specific languages) that service the various specific vertical markets serviced by GPUs, such as spatial computing, mobile devices, HPC, AI/machine learning, advanced rendering and others.
SIGGRAPH 2019 Panel Discussion
At SIGGRAPH 2019 we convened a panel discussing a proposal to extend the RISC-V open-source CPU architecture with a 64-bit GPU extension called RV-64X. The details of that discussion can be found at https://www.pixilica.com/copy-of-home.
Next Generation GPU Hardware Features and Software Features

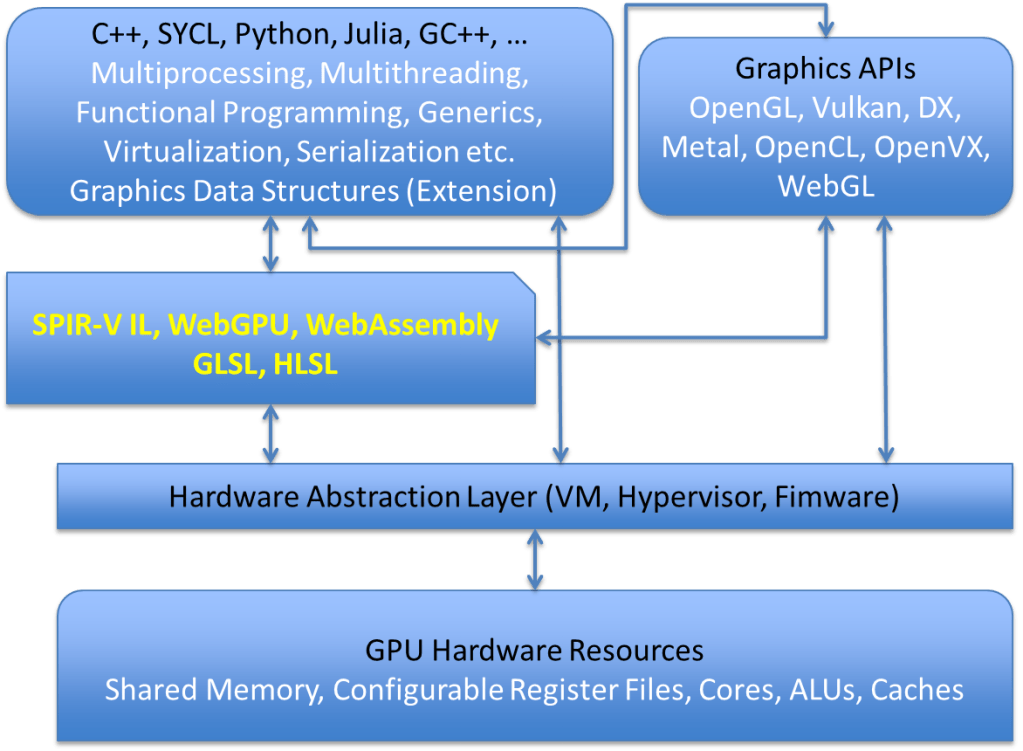
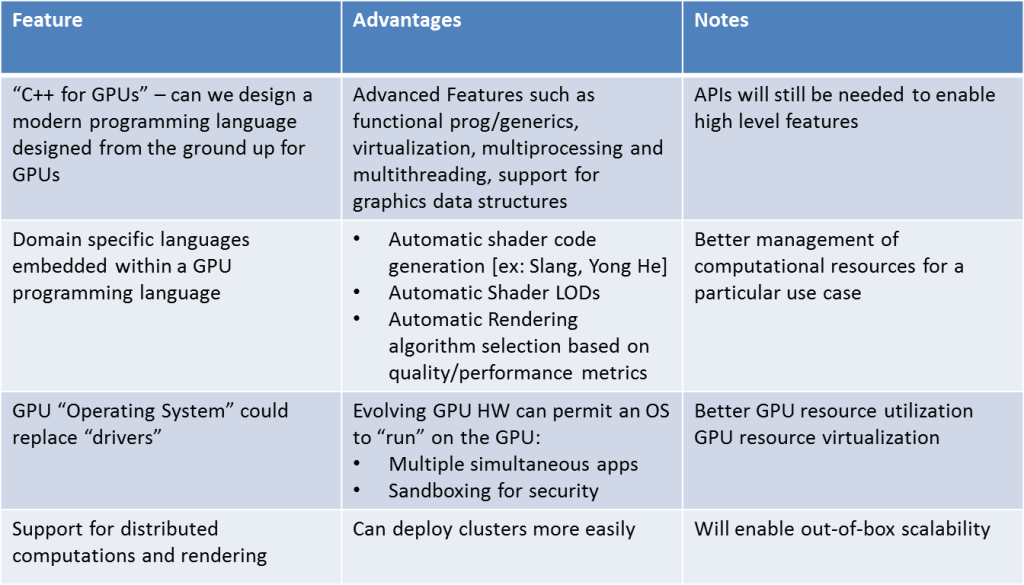
New Ideas for Graphics Rendering
The traditional 3d graphics pipeline is now 60 years old! Is it time to rethink how 3d graphics is done? Should we figure out new ways of (1) representing the world in digital form and (2) rendering it on screen? Here are some random thoughts:
- Our pixel densities are increasing. Indeed mobile devices now are keeping pace with PC displays and the pixels/inch count is constantly rising. When can we expect to have photographic quality images on a digital display? And what technology will enable that?
- In preparation for (1) can we foresee new paradigms for content development such as widespread use of real-time photogrammetry and new ways to compress and store that content? These new ways will need to also address the usability of such content, such as embedded semantic tags that tell us what this content is and how to use it.
- How can we render such content? Ray tracing? What about image-based rendering (IBR)? If the geometry resolution on a display is equal to or smaller than the pixel resolution it makes no sense to spend gigaflops figuring out the color of a single pixel! In this regard, IBR may be the ideal solution, at least in the mobile space. So a chip that can do IBR very fast? Maybe using smart-memory technology where the “capture” end of the pipeline (i.e. CCD device) is physically glued to the “processor” in a 3d stacked die ASIC with TSVs to connect the various layers including a memory layer. Does the Intel Foveros tech here make sense?
Anyway, would love to hear your comments.
Ray Tracing is the Future
With the advent of the latest GPUs from Nvidia, AMD, Microsoft and SONY touting ray tracing advances it is clear that ray (or rather path) tracing points the way to the future. Rasterization hardware (currently limited to points, lines and triangles) seems like a paltry hack to achieve realism as compared with the realistic global illumination techniques of ray and path tracing. Evolved ray/path tracing pipelines will undoubtedly be the future of graphics hardware, eliminating the clunky shader processors with their SIMT designs and constrained memory architectures.
Do we necessarily need denoising also? Can we come up with better algorithms where denoising is no longer necessary? A single ray passed through a single pixel will make a scene appear sharp. But many times we also want fuzzy effects like soft shadows and depth of field and single rays cannot achieve this. So we shoot many rays through a pixel and average the results. But this slows down the ray tracing pipeline considerably. So we instead shoot a few rays through a pixel and use image filters to “smooth” the results – this is called denoising.
But what if we instead of shooting rays we shoot “cones” or “cylinders” and hit multiple points at once and then just splat the results of what may turn out to be a point cloud, with each “point” a circle or ellipse of varying diameter? This has already been done by many researchers and involves creating a “voxelized” version of the scene using compute shaders and tracing a few cones instead of thousands of rays. The results are amazingly good! So can this function be included in next-gen hardware and APIs?
Food for thought? Comments welcome!
Get new content delivered directly to your inbox.
